



万维网
好一幢大厦!
万维网(World Wide Web)自诞生以来,已经过去17个年头了。这17年来,它改变了许多,而且从技术上看,改变仍在继续着——它提供的服务在变,它被使用的方式也在变。与此同时,由于它拥有如此之多的变化,以至于人们就“万维网到底提供了什么”这一问题莫衷一是。因此,笔者决定挑选一些万维网最具代表性的发展方向,来谈一谈它们的动向。
- 无处不在的万维网——移动Web(Mobile Web)
- 人人可用的万维网——高可用性的Web(Accessible Web)
- 包含结构化信息的万维网——语义Web(Semantic Web)
- 参与和沟通的万维网——收藏、博客、论坛
- 作为服务的万维网——富Web应用
- 适合业务的万维网——Web服务
- 适合媒体的万维网——Web上的视频和语音
以上这些发展方向应当依赖于一组共同的技术与标准,不同方面的功能应当是可以彼此互操作的。
有一些纵向问题是上述大部分发展方向所共有的,而且往往易受不同文化视角的影响。
- Web上的隐私
- Web上的安全和信任
- 知识产权问题
- 内容分类与评价
- Web的可用性
在此,我们不将介绍关于隐私、知识产权及内容分类等方面的不同看法——这些属于政治性和社会性问题。Web技术应当朝着对给定社会与政治环境有益的方向发展。
本文讲到的大部分标准和技术是W3C——万维网之父Tim Berners-Lee于1994年创建的机构——已经或正在制定的。
地基
万维网(Web)的成功归功于三项技术的组合:
- HTML:一套支持超文本(包含超链接的文本)的通用语法
- URL:一种定位文档(或其中片段)的机制,以及在HTML文档中定义超链接的方法
- HTTP:一种在客户端(通常是浏览器)与服务器之间发送请求和响应的协议
这些技术使人们可以方便地浏览Web上的文档——用户拥有一个图形用户界面,而且可以通过链接从一个文档跳转到其它相关文档。
这种由文档构成的Web迅速成为其自身成功的牺牲品。Web上的文档数量已经相当惊人了,而且它还希望能够集成来自数据库的信息。商品价目表、航班时刻表等都需要延伸到Web上。从短期来看,只需要脚本技术(服务端和客户端)以及CGI等动态网页技术就行了。不过,一种更具结构化和系统化的解决方案也是需要的。因此,我们需要对这三种基本技术加以泛化和扩展。就文档与数据的结构化来讲,需要引入XML信息集和RDF图这两个概念。
XML信息集是对HTML概念的泛化(虽然语法要更严格一点)。跟HTML一样,XML也是通过包含具名节点(named node)的树(tree)来表达文档或其他实体的结构的。HTML使用的是一套预先定义好的节点名称和语法约束规则,而XML信息集里则不包含这些约束——引入具体的约束,将形成新的数据结构或标记语言。事实上,现在有各种各样用于不同用途的XML语言。与XML有关的一些支撑技术包括:
- XML名称空间(namespace)是一种分离标签空间的机制
- XML Schema用于定义约束,从而定义新的XML语言
- XQuery/XPath用于遍历或查询XML文档
- XML Base用于处理相对URL(relative URL)
- XPointer用于引用XML文档或其中的片段
- DOM是一个处理XML的抽象接口
XML是基于一种“用简单实体来构建复杂实体”的思想,而RDF图(graph)是想通过“描述与其他实体的关系”来定义实体。RDF图由三元组(triple)组成,每个三元组都具有<主体, 谓词, 客体>的形式。其中,主体(subject)(一个资源)是你要定义的事物, 谓词(predicate)定义关系(属性),客体(object) (一个资源)是与主体具备该关系的事物。三元组中的客体(甚至谓词)可以作为另一个三元组的主体。由此,我们可以构造出一个巨大的关系网络。源于数学或逻辑的属性(property)(如“派生自”,“蕴含”等)为在RDF图上进行复杂的查询与推理奠定了基础。跟XML一样,RDF也伴随有一组相关技术:
- RDFS是一种模式语言(schema language),它定义了一套用以给资源(比如Class、Literal、Datatype等)和属性(比如subClassOf、subPropertyOf、domain、range等)赋予意义的词汇集。这就给表达集合或逻辑相关的属性开启了标准的大门。OWL是对RDFS的补充和扩展。
- SPARQL是用于RDF的查询语言。
尽管XML与RDF在信息组织上的思想不同(一个是层次化的,一个是关系化的),但它们并非完全独立于彼此。RDF/XML是一种特定的用于表示(序列化)RDF图的XML语言,尽管它并非人类可读性最好的表示方法。另外,RDF里的基本数据类型均来自XML Schema。
除上述介绍的技术,还有一系列所谓的Web架构原则,它们指出了应当如何运用这些技术来构建Web应用。
基础
我们希望Web是统一的。这一崇高目标具有几点意义。首先,它意味着,所有人都可以通过各类设备、使用他们懂的语言来访问Web。很显然,这是有其局限的(比如,本文作者可能永远无法看懂一篇用中文写的微生物学文章)。这并不意外,令人惊奇的是,我们只需遵循少许原则即可取得相当的统一。这些原则所涉领域包括:可用性(accessibility)、设备独立性(device independence)和国际化(internationalization)。
W3C是部分相关标准的制订者。最后,还有一些总体上的原则被提炼出来作为补充:
- 有标准应竭力采纳
- 表示信息时增添一些冗余
- 适当地结构化信息,可识别地呈现之
- 内容与表示相分离
有些技术是实现以上原则的共同需要。将内容与表示相分离的页面,不但可以轻松适应各种设备,而且容易满足可用性方面的需求。在文档里给一幅建筑物图片增添附加文本,不但有助于盲人理解图片内容,还可以帮助那些从没见过此建筑的人了解此建筑以及在搜索引擎里搜索它。为文本提供多种语言的版本,可令其被更多的读者阅读。采用标准化的字符集有助于进行机器翻译,等等。
Web统一的意义还远不止这些。比如,一个可用性高的网站通常更易于被搜索。(或者,如Karsten M.Self在《蜘蛛恐惧症》里所说的:“无论从哪一点看,Google都是个盲人用户。一个身价过亿的盲人用户有着上千万的朋友,每一个朋友都全神贯注地听它讲每一个词。我觉得,Google在构建高可用性网站方面,应该比美国残疾人法案(ADA)还更有影响力”)总之,注重高可用性、设备无关性和国际化(一个非常受欢迎的特性)将非常有助于提升网站的易用性和价值。
支柱
Web拥有这么多优秀的技术和知识,它能给我们带来哪些期许呢?每一项技术都是为了使我们可以更简单地做事情,它应当减少我们为达到目标所需花费的工作量。Web作为一种一般性的信息技术,它具有广泛的应用领域。与信息技术不同的是,Web是在全球网络这种规模上提供应用的。宽带连接以及近乎无限的存储与计算能力,加上互操作技术,为多媒体和巨型数据库敞开了天地。业务模型不断浮现,杀手级应用不时涌出。Web对社交网络、隐私、共享知识与智力、管理知识产权、参与决策处理、思想和产品的市场化、长尾(long tail)效应等均产生了巨大的影响。
我们看到了Web技术与移动电话技术的结合。数字移动电话于九十年代前期进入公众视线,Web也出现在同一时期。从那以后,移动电话市场的增长速度甚至超过了因特网的发展。在许多发展中国家,移动电话对经济起着至关重要的作用。现在,每部移动电话都可以上网。于是,这两种技术结合起来了。
另一方面,有些问题仍旧一筹莫展:搜索经常令人头痛,钓鱼网站和浏览器安全漏洞给用户造成威胁,自动翻译还远不能真正帮助用户理解一门他完全不懂的语言。看来,还存在不少有待解决和研究的事情,还有许多技术、社会和政治上的决策有待做出。
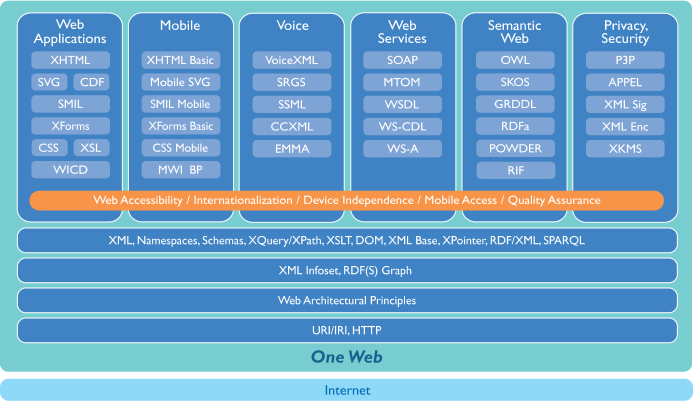
下面给出了一个对现有及研制中技术的分类:
- Web技术
- 语义Web
- Web服务
- 移动Web
- 语音通信
- 隐私与安全
Web技术
如果只是构建Web应用,那么采用纯HTML就可以了。与之相对的另一种应用,是诸如办公软件、图片处理、视频音频、复杂图像、数学或化学讲稿软件之类的功能完善的应用。通过插件和编程语言解释器,你可以把几乎所有桌面上的内容或处理搬到网页里。有不少技术为此提供支持。有些是标准化的技术,有些是私有技术;有些是“开放的”(比如提供开放源码),有些是“封闭的”。
这里面,有一些非常重要的技术与标准是由W3C提供、并且是免费和对所有人开放的。其中最广为使用就是HTML。它为嵌入遵循其他标准的对象(用于处理图像、视频、音频等)提供了标准手段。无论好坏,W3C目前正致力于两种HTML标准化的工作:HTML 5和XHTML 2。我们不打算详细描述这两种标准,对于它们,我们只是简单地概括如下:
- XHTML 2的着眼点是在HTML里更好利用XML的优势。与此同时,人们希望摈弃那些可改用更好的方式来实现的元素。它的另一设计目标是希望与其它技术或需求(复合文档、语义Web、可用性)集成。
- HTML 5更关注于推动现有HTML(HTML 4或XHTML 1)。它尽管支持XML,但并不依赖于XML。早前HTML版本的向上兼容十分重要。
的确,这两种HTML在目标和原则上都有些重叠,但它们在设计目标上是有显著差异的。
为了能够实现HTML或XML文档的内容与表现相分离,于是出现了CSS技术。它提供了一种灵活定义各元素在文档里如何表现的方式。CSS是一项非常强大的技术,在它的帮助下,Web设计者可令网页适应各种设备或屏幕尺寸。XSL是一种比CSS更一般的方法。它不仅可以格式化已有文档,还可以对文档内容进行转换。这样,就可以重组、压缩或扩展文档里的元素了。
为了允许网页用户反馈信息(如订购一个商品,或参加一场活动),可以在HTML文档里嵌入表单。表单(form)是在HTML标准里定义的。XForms是一种更为强大(而且在XML领域受到良好整合)的表单技术,所有XML语言都支持它。
SVG是一种功能强大的用于图像的XML语言。它支持基于向量的二维图形(而不是基于像素的图像),可以在没有任何质量损失的条件下对图像进行放大和缩小。SVG还支持基于向量的动画。现在许多浏览器都支持或部分支持SVG。
如前所说,(X)HTML里可以嵌入非(X)HTML对象。这些对象通常以XML文档的形式存在(如SVG或数学标记语言MathML),它们或者是通过链接来引用,或者是通过一个独立的名称空间直接包含进来。 一般来说,除非你要进行用户交互或动画同步,否则这样就可以了。有一系列复合文档标准(WICD,CDF)还在制定当中,这些标准将使得采用不同技术的文档片断可以更好的集成。
Web可以作为复杂应用的平台,特别是在强大的编程语言和接口的帮助下。所以我们可以看到很多基于Web技术的applets、widgets和应用。在CDF、XML、DOM(以及DOM事件)、XForms、XHTML和SVG等技术的支持下,游戏、地图、图像处理和全部办公套件都可以基于浏览器实现。
要构建一个包含来自各处的媒体的演示,可以采用SMIL。SMIL于1998年发布,它是一种基于XML的、用以在时间和空间上控制媒体的语言。
语义Web
在Web上寻找信息仍不是一件轻松的事。现在有许许多多的搜索引擎:基于文本的,基于主题目录的,还有一些专用搜索引擎(比如搜索最低价格的)等等。可是,除非找到专门的数据库,否则搜索“明年四月在柏林举办的所有音乐活动”还是一件很困难的事。之所以困难,是因为Web文档通常不会按搜索引擎可理解的方式来陈述“这是关于一个四月份的活动”的。当人类用户阅读此网页时,可以轻松得出结论,可搜索引擎不行。搜索引擎读到“四月”这个词时,不会知道有个活动将在该月举办,它甚至不知道这是关于一个活动的网页,也不知道这是一个什么“活动”。
要解决此问题,我们得把知识“告诉”计算机。我们可以对我们所讨论的多个事物定义关系。我们必须设法告诉计算机,“音乐是一种表演艺术”,“表演艺术是一种艺术”以及“所有音乐都有持续时间”;我们还要告诉计算机,“音乐可以现场表演”,“现场表演是一种活动”,“每场活动都具有开始时间”等等。其次,我们需要一种方式来告诉计算机,某则数据(比方说开始时间)是多少。另外,我们要能够指定这个开始时间是隶属于哪场活动的。
前面我们提到过,RDF是一种可以定义关系的语言。不过,为了能够为计算机所用,我们还需要一种唯一命名资源(resource)和属性(property)的方式——这正是URL派上用场的地方。URL创建了唯一标识Web文档的方式。不过,在技术上,URL并非只能指向网页。若取消这一限定,我们便得到URI,RDF用它来唯一标识资源(resource)和属性(property)。
属性也是资源,因此我们对属性也可以作出陈述(statement)。例如,我们可以定义一个叫“isSubClassOf”的属性,那么如果“car
isSubClassOf vehicles”而且“myCar isMemberOf car”,我们便可得知“myCar isMemberOf
vehicles”。这让我们可以利用逻辑从已有陈述中推导出新的陈述。定义属性含义的RDF词汇集(和规则)有多种。除最简单的RDFS意外,OWL标准定义了三种不同级别的词汇集:OWL,OWL Lite,OWL DL和OWL Full。各级别的OWL在关系的定义和推导上具有不同的选择。你可以采用相应的算法来进行推导(不过对于OWL
Full,算法能否在给定时间内得出结论是未知的)。
这些技术对Web意味着什么呢?我们可以设想这样一个“覆盖Web(overlay Web)”:每一个活动的开始日期,除了具有代表其自身的日期以外,还引用一个它所从属的活动;该活动不仅是一个演出,而且还是一个音乐演出。RDFa标准用于在XHTML文档里嵌入RDF陈述(statement)。
除了搜索,Web上还出现了链接数据(linked data)应用:mashup。尽管它现在一般基于私有API,旨在从一处获取数据、并将之与别处的数据合并,但采用语义Web技术来链接数据将令mashup的构建与维护简单许多。
链接数据的另一个应用是FOAF项目。它提供了用以描述人的RDF词汇。比如每个人都可以描述自己认识哪些人,这样人与人之间便建立起连接。有些社交网络应用就是基于FOAF的。
除了RDF,还有一项技术也被用于链接数据,那就是微格式(microformat)。微格式利用(X)HTML里的“class”属性来表明一个HTML元素包含一些数据。为支持互操作,微格式需进行集中管理。microformats.org上列出了现有的各种微格式。
Web服务
Web服务不太关注浏览方面,而是更关注于网络环境下软件应用之间的互操作。有一套标准专门用于实现这种互操作,并令各应用以松耦合的方式来完成复杂操作。Web服务在电子商务中扮演着重要作用。在业务步骤之间用XML来传递数据,是一项令人心动的技术,它有将部分业务流程自动化的潜力。所以,我们可以在这一领域看到许多概念和热门词汇(EAI、ESB、MOM、SOA),它们最终都是基于Web服务的。要使用Web服务,需满足以下需求:
- 需要一个在应用间交换消息的协议
- 需要一种对服务和消息进行寻址的机制
- 需要按机器可读的方式来描述服务
- 也许要应用策略来控制服务的使用
有些标准满足了Web服务的以上需求:
- SOAP规定了与服务通信时所采用消息的格式
- WS-Addressing描述了如何对Web服务和消息进行寻址
- WSDL语言用于描述一个服务的功能以及它接受/发送的消息。另外,还有一个用于对WSDL进行语义标注的标准,叫SAWSDL。它支持用本体(ontology)来表达Web服务的语义。
- Web服务策略规范定义了一种为服务的使用指定策略的方法
移动Web
移动Web的特点是,客户端设备(如移动电话)在连接性、带宽和处理能力上有比较受限。所以,移动Web标准就是要支持移动设备浏览Web,并且为之提供较好的体验。移动Web标准关注于以下方面:
- 缩减现有标准,以适应移动设备的限制
- 制定针对网页制作者(及制作工具厂商)的设计准则,以确保网站对移动设备友好
- 允许服务器了解客户端能力
XHTML Basic、SVG Tiny、SVG Basic、SMIL mobile、XForms Basic以及CSS mobile都是为满足移动设备的需要而提出标准。为了让服务器能够根据移动设备(或运行于其上的浏览器)的能力发送相应的内容,服务器需要能够了解设备的能力。DDR Simple API是一个可供服务器查询设备能力的设备描述库。
移动性的另一方面是,用户可以利用位置感知(location awareness)技术的优势。现在许多移动设备都内置有全球定位的功能。为了令服务可以利用这一信息,Geolocation API规范的制定工作已经开始了。
语音通信
有人可能想知道访问Web的最低要求是什么。用一个老式电话机可以吗?因为很多信息都是通过电话来分发和传播的,所以,提出如何令Web技术支持电话是一个相当自然的问题。使用过自动语音服务的人都知道,语音友好性在提升用户体验方面有很大的空间。为了支持更好的(半)自动化语音通信,已经有标准在制定之中了,它们涉及以下方面:
- VoiceXML用于定义对话框架。它是一种用来从用户收集信息、且具备脚本能力的XML语言。VoiceXML标记根据用户的响应来控制对话流。
- 有两个面向语音的标准支持VoiceXML。SSML是一个用于辅助合成语音生成的XML语言。SRGS用于支持为语音识别定义语法规范。
CCXML为电话呼叫控制提供支持,而且可与VoiceXML这样的对话系统联合使用。EMMA是一种 XML语言,用于描述同时接受自多个通道(如语音、手写、键盘等)的输入。
隐私与安全
Web改变了我们生活的很多方面。一个最具争议的改变是我们的隐私。我们在使用Web的过程中泄漏了许多个人数据、个人喜好及偏好等等。每当我们在网上提问,或者在网站上注册用户时,我们都在透露我们的个人信息。用户不知道这些用户信息将被收集起来作何用途。为保护公民权益,政府已经发布了隐私法。不过,由于因特网的跨国界特性,这些法案通常不适用于网络环境。这个问题不是光靠技术可以解决的。人们得慎重处理自己的隐私数据,另外我们必须寻找可被社会接受且技术上可实现的新的隐私模式。
P3P是一种按机器可读的方式描述隐私策略的标准。比如,它允许公司按用户代理(如Web浏览器)可理解的方式发布自己的隐私策略。由于无法贯彻策略,因此P3P适合于“当用户信任策略发布网站”的情形——这通常也是业务往来的前提。有些浏览器(如IE6或更新版本)采用服务器提供的P3P信息来支持用户控制cookie的使用。
有些机构是我们所信任的。不过我们如何确定我们所信任的银行网站是不是冒牌的呢?我们可以在Web上万无一失地传输机密数据吗?银行可以确信来自你的转帐请求真是你发出的吗?如何确信该请求在途中没有被篡改过?
这些不单单是Web上才有的问题。数学——尤其是数论——为我们提供了解决许多此类问题的加密手段。因特网协议支持的TLS/SSL可利用上述手段来传输数据。要在文档或数据级运用这些技术,仍有一些显著问题有待解决。XML Encryption、XML Signature和XML Key Management是三种相关技术,它们支持对XML文档片断应用一些知名的加密方法,例如对一个SOAP消息的主体进行数字签名。
关于如何评价或告知用户它们所处环境的安全上下文的工作仍在进行之中。最终,该项工作是要充分利用证书、加密、网站动态性等服务器提供的信息。这将使得用户可以在做出信任决策时更好地理解一个网站的安全上下文。
尽管该领域已经取得一些发展,但关于隐私和安全仍有不少问题有待解决。
楼顶
网站和杀手级应用
所有这些技术与标准都不是目标,而是通向目标的手段,而且目前都还不够完善。随着带宽和计算能力的不断增长,它们使得Web成为人们可以充分发挥其创造性来交易、讨论、传播想法或建立关系的场所。在过去的17年里,Web已经将因特网从少数人的玩具变成了一个强大的基础设施(infrastructure)——它由无数的个人、商人、新闻工作者、艺术家、科学家等等构成。Google、Yahoo、Flickr、Ebay、Youtube、Myspace、Wikipedia、Mozilla等仅仅构成了一小部分代表。
不过还有很多问题需要想法、技术方案、标准或社会认同来解决。现在,一方面网站、Blog、Wiki、商店以及新奇应用等在不断进步,另一方面标准与技术也在工作之中。W3C提供了一个平台,供厂商、开发者和用户来改善Web的支架。
缩略语
- ADA
- Americans with Disabilities Act/美国残疾人法案
- API
- Application Programming Interface/应用编程接口
- CCXML
- (Voice Browser) Call Control XML/(声音浏览器)呼叫控制XML
- CDF
- Compound Document Formats/复合文档格式
- CGI
- Common Gateway Interface/公共网关接口
- CSS
- Cascading Style Sheets/级联样式表
- DDR
- Device Description Repositories/设备描述库
- DOM
- Document Object Model/文档对象模型
- EAI
- Enterprise Application Integration/企业应用集成
- EMMA
- Extensible MultiModal Annotation markup language/可扩展多模式标注标记语言
- ESB
- Enterprise Service Bus/企业服务总线
- FOAF
- Friend of a Friend/朋友的朋友
- HTML
- Hypertext Markup Language/超文本标记语言
- HTTP
- Hypertext Transfer Protocol/超文本传输协议
- MathML
- Mathematical Markup Language/数学标记语言
- MOM
- Message Oriented Middleware/面向消息的中间件
- OWL
- Web Ontology Language/Web本体语言
- P3P
- Platform for Privacy Preferences/隐私偏好平台
- RDF
- Resource Description Framework/资源描述框架
- RDF/XML
- 采用XML语法的RDF
- RDFS
- RDF Schema/RDF模式
- RDFa
- RDF in attributes
- SAWSDL
- Semantic Annotations for WSDL/WSDL语义标注
- SMIL
- Synchronized Multimedia Integration Language/同步的多媒体集成语言
- SOA
- Service-Oriented Architecture/面向服务的架构
- SOAP
- Simple Object Access Protocol/简单对象访问协议(完整写法易造成误解,很少使用)
- SPARQL
- SPARQL Protocol and RDF Query Language/SPARQL协议和RDF查询
- SRGS
- Speech Recognition Grammar Specification/语音识别语法规范
- SSML
- Speech Synthesis Markup Language/语音合成标记语言
- SVG
- Scalable Vector Graphics/可伸缩向量图形
- TLS/SSL
- Transport Layer Security / Secure Sockets Layer 传输层安全/安全套接层
- URI
- Uniform Resource Identifier/统一资源标识符
- URL
- Uniform Resource Locator/统一资源定位符
- VoiceXML
- Voice Extensible Markup Language/语音可扩展标记语言
- W3C
- World Wide Web Consortium/国际万维网联盟
- WICD
- Web Integration Compound Document/Web集成复合文档
- WSDL
- Web Service Description Language/Web服务描述语言
- XForms
- 代表下一代表单的XML应用
- XHTML
- Extensible Hypertext Markup Language/可扩展超文本标记语言
- XML
- Extensible Markup Language/超文本标记语言
参考资料
W3C技术栈
<http://www.w3.org/2004/10/RecsFigure.png>
{kind=link}
关于W3C技术
<http://www.w3.org/Consortium/technology>
W3C技术报告和标准文档
<http://www.w3.org/TR/>