



Das Web
Was für ein Gebilde!
Vor 17 Jahren trat das World Wide Web erstmals in Erscheinung, und seitdem hat es vieles verändert. Noch immer verändert es sich in seiner Technologie, seinen angebotenen Diensten und deren Einsatz. Mittlerweile enthält es so viele Möglichkeiten, dass ein eindeutiger Blick auf seine Angebote sehr schwierig ist. Deswegen haben sich die Autoren entschieden, einige Entwicklungen auszuwählen, die sie als Hauptrichtung ansehen und somit einen Eindruck dessen vermitteln, was gerade abläuft.
- Web überall - mobiles Web
- Web für alle - erreichbares Web
- Web der strukturierten Informationen - Semantic Web
- Web der Mitwirkung und Kommunikation - Sammlungen, Blogs und Foren
- Web der Dienste - Rich Web Anwendungen
- Web für Geschäfte- Web Services
- Mediales Web - Video und Sprache im Web
All diese Dinge sollten auf einer gemeinsamen Anlage von Technologien und Standards beruhen. Die Funktionsweisen der verschiedenen Aspekte sollten zusammenarbeiten.
Einige andere Themen sind für die meisten dieser Aspekte relevant. Sie sind von Natur aus horizontal und einige davon unterliegen unterschiedlicher kultureller Ansichten.
- Datenschutz im Web
- Sicherheit und Vertrauen im Web
- Umgang mit geistigem Eigentum
- Klassifizierung und Bewertung von Inhalten
- Barrierefreies Internet
Wir werden hier nicht die verschiedenen Ansichten über z. B. Datenschutz, geistiges Eigentum und der Bewertung von Inhalten abdecken. Diese sind noch immer Gegenstand politischer und sozialer Diskussionen, während sich Webtechnologien dem annähern sollten, was in einem sozialen und politischen Kontext als nützlich betrachtet wird.
Der größte Anteil der hier beschriebenen Arbeit an Standards und Technologien wird oder wurde vom W3C durchgeführt, das 1994 von Tim Berners-Lee, dem Erfinder des Web, ins Leben gerufen wurde.
Das Fundament
Drei miteinander kombinierte Technologien machten den Erfolg des Web aus:
- Eine gemeinsame Syntax für Dokumente, die Hyperlinks enthalten dürfen (HTML)
- Eine Syntax, die Dokumente (oder Teile von Dokumenten) lokalisiert, und die Möglichkeit, diese Syntax innerhalb von HTML zu nutzen, um Hyperlinks zu generieren (URL)
- Ein Protokoll, um Anfragen und Antworten zwischen Clients (normalerweise Browsern) und Servern zu versenden (HTTP)
Diese Technologien erlaubten es, ein globales Netz an Dokumenten aufzuspannen, das - aus Benutzersicht - eine grafische Benutzeroberfläche anbot un außerdem einen sehr einfachen Weg ermöglichte, mithilfe eines Links in einem Dokument in ein anderes zu gelangen.
Dieses Web der Dokumente wurde schnell ein Opfer seines Erfolges. Es gab eine riesige Menge an Dokumenten und das Verlangen, Informationen aus Datenbanken zu integrieren. Einkaufsangebote, Flugpläne... etc. verlangten eine Erweiterung des Konzepts. Kurzfristig waren es die Skriptsprache (der Server- und der Client-Seite) und CGI, die dynamische Websites in Betracht zogen. Jedoch gab es auch einen Bedarf an besser strukturierten und systematischeren Lösungen. Deshalb musste eine Verallgemeinerung und eine Erweiterung der drei ursprünglichen Technologien vorgenommen werden. Bezüglich der Strukturierung der Dokumente und der Daten wurden zwei Konzepte eingeführt: das XML Infoset und die RDF-Graphen.
Das XML Infoset stellt eine Verallgemeinerung des HTML Konzeptes dar (jedoch mit strengeren Regelungen im Bereich der Syntax). Ebenso wie HTML strukturiert XML ein Dokument oder andere Datensätze mittels eines Baumes mit benannten (tagged) Knoten. HTML verwendet einen vordefinierten Satz an Knotennamen und Regeln, die ihren Gebrauch innerhalb eines Dokuments beschränken. Das XML Infoset enthält keine solchen Einschränkungen. Die Einführung spezieller Einschränkungen kann dazu genutzt werden, neue Datenstrukturen oder Auszeichnungssprachen zu bilden. In der Tat gibt es heute tausende dieser XML Sprachen, die viele verschiedene Zwecke erfüllen. Zusammen mit XML erschienen einige unterstützende Technologien:
- XML Namensräume als ein Mittel, um eine Menge von Tags von anderen zu trennen
- XML Schema, das eine Definition der Einschränkungen ermöglicht, um eine neue XML Sprache zu spezialisieren
- Xquery/Xpath als ein Mittel, durch XML Dokumente zu navigieren oder Anfragen an diese zu stellen
- XML Base, um relative urls zu beherrschen
- Xpointer, um eine Referenz auf XML Dokumente und Fragmente zu ermöglichen
- DOM: eine abstrakte Schnittstelle, um XML zu verarbeiten
XML beruht auf dem Konzept, komplexe Einheiten zu definieren und sie aus einfacheren zusammenzusetzen. RDF-Graphen versuchen Einheiten zu definieren, indem sie deren Verhältnis zu anderen beschreiben. Ein RDF-Graph besteht aus Tripel der Form Subjekt Prädikat Objekt. Während Subjekt (Ressource) etwas bezeichnet, das definiert werden soll, definiert Prädikat (Eigenschaft) die Beziehung. Das Objekt (Ressource) ist etwas, für das die Beziehung gilt. Objekte (und sogar Prädikate) in einem Tripel können in anderen wiederum als Subjekte erscheinen. Deshalb können wir riesige Netzwerke an Beziehungen sehen. Eigenschaften, die ihren Ursprung in der Mathematik oder der Logik haben ( z. B. "ist eine Teilmenge von", "impliziert"...), bilden die Grundlage für komplexe Anfragen und Schlussfolgerungen in diesen Netzwerken. Wie XML besitzt auch RDF eine Menge dazugehöriger Technologien:
- RDFS ist eine Schemasprache, die ein Vokabular definiert, das einigen Ressourcen (wie Class, Literal, Datatype...) und Eigenschaften (wie subClassOf, subPropertyOf, domain, range...) eine Bedeutung gibt. Dies öffnet einen standardisierten Weg, eine Menge an oder logisch verbundene Eigenschaften auszudrücken. OWL ergänzt und erweitert diese Definitionen.
- SPARQL ist eine Anfragesprache für RDF
Obwohl XML und RDF bezüglich der Informationsstrukturierung verschiedenen Konzepten folgen - hierarchisch und relational -, kann man sie nicht vollständig voneinander trennen. RDF/XML ist eine spezielle XML Sprache, um RDF-Graphen darzustellen (serialisieren) - allerdings nicht die visuell am besten lesbare. Grundlegende Datentypen in RDF stammen von XML Schema.
Neben den hier vorgestellten Technologien, gibt es eine Sammlung sogenannter Web Architecture Principles, die Regeln festlegen, wie aus diesen Technologien neue entwickelt werden können.
Eckpfeiler
Wir wollen, dass das Web universell ist. Dies ist ein nobler Anspruch mit etlichen Auswirkungen. Letztendlich bedeutet dies, dass jeder das Web mit einer großen Auswahl von Geräten in jeder ihm bekannten Sprache nutzen können soll. Es ist ziemlich offensichtlich, dass es dabei Beschränkungen gibt (z. B. wird der Autor dieser Zeilen nie in der Lage sein, einen Artikel über Mikrobiologie in chinesischer Sprache zu verstehen). Dies ist keine Überraschung. Vielmehr ist das Überraschende, wie viel Allgemeingültigkeit erreicht werden kann, wenn einige Richtlinien befolgt werden. Die Bereiche, für die diese Richtlinien entwickelt werden, sind: Barrierefreiheit, Geräteunabhängigkeit und Internationalisierung.
W3C ist ein Entwickler einiger dieser Richtlinien. Letztlich gibt es einige allgemeine Regeln, die weiterentwickelt und ergänzt werden:
- Benutze Standards, wann immer dies möglich ist!
- füge Redundanz in die Präsentation deiner Informationen ein
- Strukturiere Deine Information genau und mache die Struktur transparent!
- Trenne den Inhalt von der Darstellung!
Es gibt Überschneidungen in den technischen Anforderungen, um dies zu erreichen. Eine Seite, die Inhalt und Darstellung trennt, kann leichter an die verschiedenen Geräte und an die Zugangserfordernisse angepasst werden. Ein Bild eines Gebäudes in einem Dokument, welches von einem Text begleitet wird, könnte einer blinden Person helfen, es zu verstehen. Es kann aber auch jemandem, der z. B. das Gebäude zuvor noch nie gesehen hat oder einer Suchmaschine bei der Identifikation helfen. Texte erreichen mehr Menschen, wenn durch Vielsprachigkeit Redundanz hinzugefügt wird.Die Verwendung standardisierter Zeichensätze hilft, unter anderem, der maschinellen Übersetzung...
Die Auswirkungen gehen jedoch noch über die hier erwähnten Gegenstände hinaus. So ist z. B. eine erreichbare Website normalerweise besser durchsuchbar. (Oder wie Karsten M. Self in Arachnophobia behauptete: "Google ist im Grunde ein blinder Nutzer. Ein Millionär, ein blinder Nutzer mit zehntausenden Freunden, die alle an seinen Lippen hängen. Ich vermute, Google wird auf die Entwicklung erreichbarer Websites eine größere Auswirkung haben als die ADA."). Im Allgemeinen gilt: Barrierefreiheit, Geräteunabhängigkeit und Internationalisierung anzustreben, trägt - als sehr willkommener Nebeneffekt - bezeichnenderweise zur Benutzerfreundlichkeit und zum Wert einer Site bei.
Tragende Säulen
Was können wir also mit all diesen feinen Technologien und dem Wissen vom Web erwarten? Jede Technologie ist dazu da, unser Leben einfacher zu gestalten. Sie sollen die Mühe, die wir aufbringen, um unsere Ziele zu erreichen, reduzieren. Wie Informationstechnologie im Allgemeinen bietet das Web ein breites Spektrum an Anwendungsgebieten an. Anders jedoch als Informationstechnologie bietet das Web diese Anwendungen vernetzt in einem globalen Ausmaß an. Breitband-Internetzugang und beinahe unbegrenzte Speicherung und Rechenleistung öffnen zusammen mit kompatiblen Technologien den Raum für Multimedia und riesige Datenbanken. Geschäftsmodelle steigen auf und stürzen ab, Killerapplikationen tauchen auf. Dinge wie soziale Netzwerke, der Datenschutz, das Teilen von Wissen und Information, die Regelung des geistigen Eigentums, die Beteiligung an Entscheidungsprozessen, die Vermarktung von Ideen und Produkten, die Bedeutung des long tail,... müssen überdacht werden oder werden erst relevant,wenn sie auf dem Web beruhen.
Wir erkennen eine Konvergenz der Webtechnologien mit der Mobilfunktechnologie. Digitale Mobiltelefone tauchten in der ersten Hälfte der 90er Jahre in der Öffentlichkeit auf - gleichzeitig mit dem Web. Seitdem überragte das Wachstum dieses Marktes sogar den des Internets. Mobiltelefone spielen in vielen Entwicklungsländern eine entscheidende wirtschaftliche Rolle. Heutzutage hat jedes Mobiltelefon Zugriff auf das Web, und somit fließen beide Technologien ineinander.
Andererseits gibt es noch einige Dinge, die im Argen liegen. Das Suchen kann schnell zum Albtraum werden. Außerdem bedrohen Phishing und der Missbrauch von Browserschwachstellen die Benutzer. Automatische Übersetzungen sind noch nicht in der Lage, Informationen in Sprachen, die der Benutzer nicht beherrscht, abzurufen. Es gibt also noch viel auszubessern und zu erforschen! Auch sollten noch viele technische, soziale und politische Entscheidungen getroffen werden.
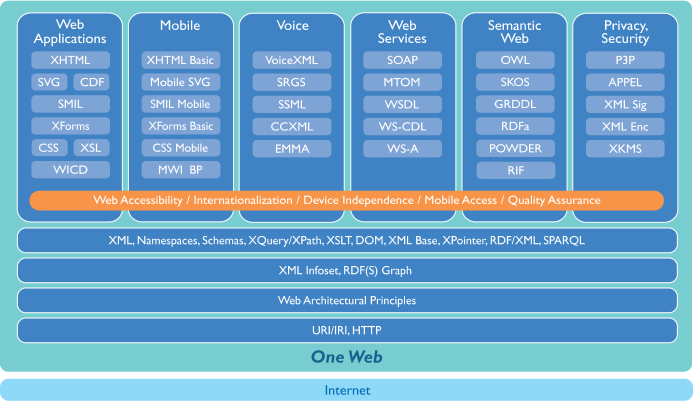
Eine Klassifizierung der Technologien, die bereits verfügbar oder noch in der Entwicklungsphase sind, könnte durch folgende Themen erfolgen:
- Webanwendungen
- Semantic Web
- Web Services
- Mobiles Web
- Sprachkommunikation
- Datenschutz und Sicherheit
Webanwendungen
Um eine Webanwendung zu erstellen, braucht man nur HTML. Am anderen Ende des Spektrums sind vollständige Anwendungen z. B. für die Büroarbeit oder die Bildbearbeitung. Mitinbegriffen können Video- und Audioapplikationen, schwierige Grafiken und auf Präsentation bezogene Software für Mathematik oder Chemie sein. Plugins und Übersetzer für Programmiersprachen erlauben es fast jedem Inhalt und jeder Entwicklung , die auf einem Desktop funktionieren, innerhalb einer Website benutzt zu werden. Es gibt etliche verfügbare Technologien, die dies unterstützen. Einige davon sind standardisiert, andere sind proprietär. Einige sind "offen" (z. B. durch anbieten von Open Source), andere sind "geschlossen".
Einige der wichtigsten Technologien und Standards in diesem Kontext werden von W3C zur Verfügung gestellt. Sie sind gebührenfrei und für jeden zugänglich. Unter diesen Standards ist HTML der am weitesten verbreitete. Außerdem ist es der Standard, der Mittel zur Verfügung stellt, um Objekte, die anderen Standards folgen, einzubauen. Auf diese Weise ermöglicht er die Erstellung von Grafiken, Videos, Bildern... Tatsache ist, dass es heute zwei durch W3C standardisierte HTML gibt; und zwar HTML 5 und XHTML 2. Hier ist jedoch nicht der Ort, um ins Detail zu gehen. Trotz der Gefahr der Vereinfachung könnte man diese beiden Richtungen wie folgt charakterisieren:
- Das Hauptziel von XHTML 2 ist die bessere Nutzung der Vorteile von XML innerhalb von HTML. Gleichzeitig sollen die Konstrukte (Elemente) beseitigt werden, deren Funktionalität besser und sauberer durch allgemeinere Konstrukte implementiert werden könnten. Die Integration anderer Technologien oder Aufgaben (Compound Documents, Semantic Web, Barrierefreiheit) stellt ein weiteres Ziel des Designs dar.
- HTML 5 soll eher das bereits vorhandene HTML (HTML 4 oder XHTML 1) weiterentwickeln. Es basiert nicht zwangsläufig auf XML, obwohl es seine Verwendung unterstützt. Aufwärtskompatibilität mit früheren Versionen von HTML ist jedoch sehr wichtig.
Natürlich gibt es einige Überschneidungen, was die Zielvorgaben und die Prinzipien beider HTML angeht, jedoch sind die Unterschiede ihrer Gestaltungsziele entscheidend.
Um eine Trennung der Präsentation vom Inhalt der HTML- oder der XML Dokumente zu ermöglichen, wurde eine Technologie namens CSS entwickelt. Diese verfügt über flexible Mittel, die für jedes Element die Präsentationsform innerhalb des Dokuments definieren. CSS ist eine sehr leistungsstarke Technologie, die es Webdesignern ermöglicht, ihre Seiten auf eine Vielzahl von Geräten und Fenstergrößen anzuwenden. Ein eher allgemeiner Ansatz ist XSL. XSL ermöglicht es nicht nur, bereits vorhandene Dokumente zu formatieren, sondern auch deren Inhalt zu transformieren. Die Elemente eines Dokuments können also umgestaltet, komprimiert oder ausgeweitet werden.
Um dem Leser einer Website eine Rückmeldung zu ermöglichen (z. B. um einen geschäftlichen Auftrag zu erteilen oder sich für eine Veranstaltung anzumelden), können HTML Dokumente Webformulare enthalten. Sie sind ein Teil des HTML Standard. Leistungsstärker -und richtig integriert in die XML Welt- ist Xforms, das mit jeder XML Sprache genutzt werden kann.
Eine sehr leistungsstarke XML Sprache im Bereich der Grafik ist SVG. Es ermöglicht vektor-basierende zweidimensionale Grafiken, die -anders als die auf pixel- basierenden Abbilder- vergrößert und verkleinert werden können, ohne dabei an Qualität zu verlieren. SVG ermöglicht des weiteren vektor-basierende Animationen. Viele modernen Browser unterstützen SVG oder eine Untergruppe davon.
Wie bereits erwähnt, ist (X)HTML in der Lage, Objekte anderer Standards einzubeziehen. Diese werden entweder durch einen Link bezeichnet oder direkt eingefügt - oftmals als XML Dokument mit einem anderen Namensraum (z.B. SVG oder die mathematische Auszeichnungssprache MathML). Normalerweise sollte das gut funktionieren, außer es soll eine Benutzerinteraktion oder eine Synchronisation von Animationen stattfinden. Es wird eine Reihe von Standards von Compound Documents geben (WICD, CDF...), die eine bessere Integration der Dokumententeile ermöglichen, wenn diese auf verschiedene Technologien zurückgreifen.
Das Web kann -besonders wenn es in Verbindung mit leistungsstarken Programmiersprachen und Schnittstellen benutzt wird- kann als Plattform für komplizierte Anwendungen dienen. Somit haben wir viele kleine Anwendungen, Widgets und Anwendungen, die auf Webtechnologien beruhen. Spiele, Karten, Bildbearbeitungen oder vollständige Office-Pakete usw. können auf Browsern beruhen, die Technologien wie z. B. Compound Document Format, XML, DOM (sowie DOM Events), Xforms, XHTML, SVG und einige andere verwenden.
Um Präsentationen mit Datenträgern verschiedener Quellen zu synchronisieren, könnte man SMIL benutzen. SMIL wurde 1998 veröffentlicht. Es handelt sich um eine XML Sprache, die es ermöglicht, Datenträger nach Zeit und Ort anzuordnen.
Semantic Web
Es ist noch immer eine große Herausforderung, Dinge im Web zu finden. Es gibt dort viele Suchmaschinen - entweder basierend auf Texten oder Themenkatalogen oder aber spezielle Maschinen wie bspw. Maschinen, die nach den niedrigsten Preisen suchen. Dennoch ist es sehr schwierig, z. B. alle Musikereignisse, die nächstes Jahr im April in Berlin stattfinden, zu finden, wenn man auf keine spezialisierte Datenbank zurückgreifen kann. Das liegt daran, dass Webdokumente normalerweise nicht anzeigen "hierbei handelt es sich um eine Veranstaltung, die im April stattfindet"; zumindest nicht so, dass Suchmaschinen es verstehen können. Ein Mensch kann dies normalerweise problemlos folgern, im Gegensatz zur Suchmaschine. Sie findet zwar das Wort "April", hat jedoch keine Ahnung, dass es sich dabei um den Monat handelt, in dem das Ereignis stattfindet. Sie weiß nicht einmal, dass sich die Seite um eine Veranstaltung handelt oder was eine Veranstaltung sein könnte. Dasselbe geschieht bei dem Wort "Musik".
Um dieses Problem zu lösen, müssen wir dem Computer etwas "beibringen". Dies geschieht durch eine Definition der Beziehung der vorhandenen Dinge. Wir müssen Möglichkeiten finden, um dem Computer mitzuteilen, dass Musik eine Performance ist. Dass jede Performance eine Kunst ist und dass jede Art von Musik eine Dauer hat. Musik kann eine Live Performance sein, und jede Live Performance ist ein Ereignis, das eine Anfangszeit hat usw. Außerdem brauchen wir eine Möglichkeit, um dem Computer klar zu machen, dass ein bestimmtes Datenstück z. B. die Anfangszeit ist. Desweiteren müssen wir die Anfangszeit dem Ereignis zuordnen können.
Es wurde bereits erwähnt, dass RDF eine Sprache ist, die es uns ermöglicht, über Beziehungen zu sprechen. Um jedoch für den Computer nutzbar zu sein, brauchen wir zudem einen eindeutigen Weg, Eigenschaften und Ressourcen zu benennen. Hier kommt die URL Konzept gelegen. URL stellt eine Möglichkeit dar, Webdokumente eindeutig zu identifizieren. Es gibt aber keinen technischen Grund, die Mechanismen von URLs auf Websites zu beschränken. Wenn diese Beschränkungen aufgehoben werden, erhalten wir das URI, das RDF zur eindeutigen Identifikation der Eigenschaften und der Ressourcen benutzt.
Eigenschaften sind auch Ressourcen. Somit können wir Aussagen über Eigenschaften machen. So könnten wir z. B. definieren, dass eine Eigenschaft "isSubClassOf" und daraus schließen, dass, wenn "car isSubClassOf vehicles" und "myCar isMemberOf car", dann ergibt sich "myCar isMemberOf vehicles". Somit ergeben sich durch logische Anwendungen neue Aussagen aus bereits vorhandenen. Es gibt verschiedenen RDF Beschreibungssprachen, die die Bedeutung solcher Eigenschaften definieren. Abgesehen von der einfachsten RDFS, gibt es (heutzutage) drei standardisierte Ebenen , die OWL: OWL Lite, OWL DL und OWL Full. Jede Ebene bietet verschiedene Möglichkeiten, um Verbindungen zu spezifizieren und Schlussfolgerungen zu erstellen. Es gibt Algorithmen, die dabei helfen, solche Schlussfolgerungen zu finden (und irritierenderweise ist es im Allgemeinen nicht sicher, dass Algorithmen, die OWL Full verarbeiten, jemals enden werden).
Was bedeuten diese Technologien nun für das Web? Wir könnten uns ein überlagertes Web vorstellen, in dem z.B. jede Anfangszeit einer Veranstaltung sich selbst als Anfangszeit definiert, sich auf sein Ereignis bezieht, das sich selbst als eine Performance identifiziert und zudem sich als Musik erkennt... Es gibt den Standard RDFa, der es ermöglicht, RDF Aussagen in ein XHTML Dokument einzufügen.
Neben der Suche ist eine weitere Verwendung verlinkter Daten aufgetaucht: das Mashup. Obwohl es heute oftmals auf proprietären APIs basiert, ist die Idee dahinter, Daten aus einer Quelle mit Informationen einer anderen zu mischen. Technologien des Semantic Web, um die Daten zu verlinken, würde die Konstruktion und die Erhaltung des Mashup sehr erleichtern.
Ein weiteres Beispiel, verlinkte Daten zu verwenden, ist das FOAF Projekt. Es stellt eine RDF Beschreibungssprache zur Verfügung, um eine Person zu beschreiben. Ein Teil der Beschreibung können Daten über jemanden sein, der diese Person kennt - was zu einer weiteren FOAF Beschreibung führen oder eine enthalten kann. Einige offenen sozialen Netzwerke basieren auf FOAF.
Neben RDF wird eine weitere Technologie gebraucht, um Daten im Web zu verlinken: Mikroformate. Sie nutzen das "class"-Attribut von (X)HTML, um anzuzeigen, dass ein HTML Element Daten enthält. Um dialogfähig zu sein, müssen Mikroformate zentral verwaltet werden. Spezifikationen von Mikroformaten sind unter www.microformats.org verfügbar.
Web Services
Web Services haben eigentlich nichts mit surfen zu tun. Vielmehr geht es dabei um die Interoperation von Softwareanwendungen in Computern, die durch ein Netzwerk miteinander verbunden sind. Eine Reihe von Standards helfen dabei, diese Interoperabilität zu gewährleisten, sowie die Anwendungen lose zu koppeln, dass komplexe Operationen durchgeführt werden können. Vor allem im E-Business spielen Web Services eine zentrale Rolle. Die Gelegenheit, Daten von einem zum nächsten Geschäftsabschnitt mithilfe eines XML Datenformats zu reichen, erscheint sehr reizvoll. Außerdem besteht die Möglichkeit, Teile des Geschäftsablaufs zu automatisieren. Es gibt also viele Konzepte und Schlagworte (EAI, ESB, MOM, SOA...) in diesem Bereich, die letztlich auf Web Services basieren. Einige Anforderungen müssen jedoch erfüllt sein, damit Web Services so funktionieren:
- Man braucht ein Protokoll, um Meldungen zwischen den Anwendungen auszutauschen
- Man muss Dienste und Meldungen anwählen können
- Man muss die Dienste maschinenlesbar beschreiben
- Man möchte Regeln für die Steuerung und Nutzung von Web Services aufstellen und anwenden
Es gibt einige Standards, die die Grundlage der Web Services, die auf diesen Anforderungen basieren, bilden:
- SOAP spezifiziert das Format der Meldungen, die benutzt werden können, um mit einem Dienst zu kommunizieren
- WS-Addressing erlaubt es, Adressinformationen auszutauschen
- WSDL ist eine Sprache, um einen Dienst nach der Art seiner Meldungen zu beschreiben. Es gibt außerdem einen Standard für Semantische Annotationen für WSDL (SAWSDL), der den Gebrauch von Ontologien erlaubt, um die Semantik der Web Services zu täuschen
- der Web Services Policy Standard ermöglicht es Regeln für die Nutzung eines Web Service zu erstellen und mit dem Service zu verbinden
Das mobile Web
Die mobile Nutzung des Web wird durch Geräte mit limitierter Leistungsfähigkeit gekennzeichnet (z. B. Mobiltelefone). Dies bezieht sich auf Verbindungsfähigkeit, Bandwidth und Rechenleistung des Client. Also handeln Mobile Web Standards davon, Browsing zu ermöglichen und die Nutzung mobiler Geräte positiv zu gestalten. Mobile Web Standards konzentrieren sich auf zwei Aspekte:
- Verkleinerung der vorhandenen Standards, um sei an die Möglichkeiten der mobilen Geräte anzupassen
- Die Entwicklung von Richtlinien speziell für Autoren (aber auch für Hersteller von Authoring-Tools), die eine "mobil-freundliche" Website sicherstellen
- Eine Möglichkeit für Server, die Leistungsfähigkeit eines verbundenen Client zu erkennen
XHTML Basic, SVG Tiny, SVG Basic, SMIL mobile, Xforms Basic und CSS mobile sind Standards, die diejenigen Module der jeweiligen Technologien umfassen, die mobile Geräte bereitstellen sollten. Um die inhaltliche Zufuhr eines Servers auf die Leistungsfähigkeit eines mobilen Gerätes zuzuschneiden, sollte der Server die Fähigkeiten des Gerätes erlernen können. DDR simple API beschreibt ein Interface, auf das Server zurückgreifen können, um ein DDR, welches diese Information enthält, abzufragen.
Ein weiterer, für den Benutzer positiver, Aspekt der Mobilität liegt in der Kontextsensitivität. Viele mobilen Geräte haben die eingebaute Fähigkeit, ihre Position auf dem Globus zu orten. Um diese Information für den Benutzer zugänglich zu machen, hat man mit der Arbeit an einer Spezifikation von Geolocation API begonnen.
Sprachkommunikation
Man könnte sich über die geringen Anforderungen wundern, die erfüllt sein müssen, um ins Web zu gelangen. Würde ein einfaches altes Telefon auch reichen? Manchmal zumindest? Schließlich wird einiges an Information über das Telefon verbreitet und kommuniziert. Deshalb ist es angemessen zu fragen, wie dies durch Webtechnologien unterstützt werden könnte. Jeder, der schon einmal über einen Computer telefoniert hat weiß, dass -nett ausgedrückt- noch Raum für mehr Benutzerfreundlichkeit ist. Um den Weg für bessere (halb)automatische Sprachkommunikation zu ebnen, wurden einige Standards entwickelt, die folgende Bereiche abdecken:
- VoiceXML definiert Dialog Frameworks. Es handelt sich um eine Auszeichnungssprache, die Informationen eines Benutzers sammelt. Der Dialogfluss wird durch die VoiceXML Markup kontrolliert und hängt von den Antworten der Benutzer ab. VoiceXML ist eine XML Sprache mit Scriptmöglichkeiten.
- Zwei sprachorientierte Standards unterstützen den Gebrauch von VoiceXML. SSML ist eine auf XML basierende Sprache, die die Erzeugung synthetischer Sprache unterstützen soll. SRGS spezifiziert Spracherkennungs-Grammatiken.
CCXML bietet Unterstützung bei der Telefonie-Kontrolle an und kann in Zusammenhang mit Dialogsystemen wie z.B. VoiceXML verwendet werden. Bei EMMA handelt es sich um eine XML Sprache, die den Input beschreibt, der über mehrere Kanäle gleichzeitig erhalten wird (über Stimme, Handschrift, Tastatur...)
Datenschutz und Sicherheit
Das Web hat unser Leben in vielerlei Hinsicht verändert. Eine der zwiespältigsten Veränderungen ist die in unserer Privatsphäre. Während wir das Web benutzen, geben wir viele unserer privaten Daten, unserer Interessen und Vorlieben preis. Jede Frage, die wir stellen und jede Website, die wir besuchen, kann registriert werden. Für den Benutzer ist es schwer zu erahnen, wie diese Informationen verwendet werden. Um seine Bürger zu schützen, haben Regierungen Datenschutzgesetze erlassen. Jedoch endet deren Geltungsbereich an den Landesgrenzen, und somit ist der Effekt auf das Internet beschränkt. Dieses Problem kann nicht alleine mit technischen Mitteln beseitigt werden. Vielmehr müssen die Menschen vorsichtig und sozial akzeptabel mit ihren persönlichen Daten umgehen. Außerdem müssen neue Datenschutzmodelle gefunden werden, die technisch praktisch anwendbar sind.
P3P ist ein Standard, der eine maschinenlesbare Beschreibung von Datenschutzrichtlinien spezifiziert. Beispielsweise ermöglicht er Firmen, ihre Datenschutzrichtlinien so zu veröffentlichen, dass der User Agent sie verstehen kann (z. B. als Teil eines Webbrowser). Da es keine Möglichkeit gibt, den Datenschutz zu erzwingen, ist P3P in den Fällen sinnvoll, in denen der Benutzer den Sites, die eine Richtlinie erstellen, vertrauen kann. Davon geht man im Normalfall aus, wenn man Geschäfte macht. Einige Browser (z. B. Internet Explorer 6 und später) verwenden P3P Information, die die Server ihnen anbieten, um den Benutzern die Kontrolle des Einsatz von Cookies zu ermöglichen.
Es gibt Institutionen, denen wir vertrauen. Können wir aber sicher sein, dass die Website, die scheinbar die Homepage unserer Bank ist, auch wirklich unsere Bank ist? Können wir vertrauliche Daten sicher über das Web transferieren? Kann Ihre Bank sichergehen, dass die von Ihrem Konto getätigte Geldüberweisung auch wirklich von Ihnen ausgestellt wurde? Dass sie nicht auf dem Weg verändert wurde?
Diese Probleme sind jedoch nicht nur spezifisch für das Web. Die Mathematik -speziell die Zahlentheorie- hat als Hilfsmittel die Verschlüsselung zur Verfügung gestellt, die viele Probleme auf diesem Gebiet löst. Die mit TLS/SSL ausgestatteten Internetprotokolle wenden diese Mittel auf den Datentransfer an. Es gibt jedoch noch einiges, was offensichtlich noch einer Lösung bedarf, damit diese Technologie auf die Dokumenten- oder Datenebene angewendet werden kann. XML Encryption, XML Signature und XML Key Management sind drei ähnliche Technologien, die eine Anwendung auf bekannte kryptographische Methoden auf XML Dokumente ermöglichen (z. B. SOAP Message).
Die Frage, wie Benutzer über den Sicherheitskontext ihres Milieus informiert bzw. wie dieser ausgewertet werden soll, liefert permanent Arbeit. Letztlich geht es darum, wie die Verwendung von Zertifikaten, Verschlüsselung, dynamischen Websites und anderen Serverinformationen verbessert werden kann. Dies sollte die Benutzer befähigen, den Sicherheitskontext einer Website besser nachzuvollziehen, wenn sie vertrauliche Entscheidungen durchführen.
Obwohl große Fortschritte in diesem Bereich zu sehen sind, gibt es noch etliche ungelöste Probleme hinsichtlich Datenschutz und Sicherheit.
Das Dach
Websites und Killerapplikationen
All diese Technologien und Standards sind eher ein Mittel zum Zweck als Ziele an sich, und die Liste ist noch längst nicht vollständig. Zusammen mit stetig zunehmender Bandwidth und Rechenleistung, machen sie das Web zu einem Ort, an dem die Menschen ihre Kreativität nutzen, um Geschäfte zu machen, Diskussionen zu führen, Ideen zu verbreiten oder Verbindungen aufzubauen. In den letzten 17 Jahren hat das Web das Internet von einem Spielzeug der Computerfreaks hin zu einer einflussreichen Infrastruktur verändert, die sich aus Millionen von Individuen, Geschäftsleuten, Journalisten, Autoren, Wissenschaftlern … zusammensetzt. Google, Yahoo, Flickr, Ebay, Youtube, Myspace, Wikipedia und Mozilla sind nur einige der bekannten Projekte, die in diesem Raum leben.
Es gibt jedoch noch viele offene Fragen, die auf Antworten in Form von Ideen, technischen Lösungen, Standards oder sozialen Übereinkommen warten. Neben der Arbeit an Millionen von Websites, Blogs, Wikis, Shops und originellen Anwendungen, gibt es eine ständige Arbeit an einer Verbesserung der Standards und der Technologien. W3C bietet einen Rahmen, in dem Anbieter, Autoren und Benutzer an einer Verbesserung des Tragrahmens des Web zusammenarbeiten.
Abkürzungen
- ADA
- Americans with Disabilities Act
- API
- Application Programming Interface
- CCXML
- (Voice Browser) Call Control XML
- CDF
- Compound Document Formats
- CGI
- Common Gateway Interface
- CSS
- Cascading Style Sheets
- DDR
- Device Description Repositories
- DOM
- Document Object Model
- EAI
- Enterprise Application Integration
- EMMA
- Extensible MultiModal Annotation markup language
- ESB
- Enterprise Service Bus
- FOAF
- Friend of a Friend
- HTML
- Hypertext Markup Language
- HTTP
- Hypertext Transfer Protocol
- MathML
- Mathematical Markup Language
- MOM
- Message Oriented Middleware
- OWL
- Web Ontology Language
- P3P
- Platform for Privacy Preferences
- RDF
- Resource Description Framework
- RDF/XML
- RDF in XML Syntax
- RDFS
- RDF Schema
- RDFa
- RDF in attributes
- SAWSDL
- Semantic Annotations for WSDL
- SMIL
- Synchronized Multimedia Integration Language
- SOA
- Service-Oriented Architecture
- SOAP
- (originally for) Simple Object Access Protocol (long version is misleading and not used anymore)
- SPARQL
- Protocol and RDF Query Language
- SRGS
- Speech Recognition Grammar Specification
- SSML
- Speech Synthesis Markup Language
- SVG
- Scalable Vector Graphics
- TLS/SSL
- Transport Layer Security / Secure Sockets Layer
- URI
- Uniform Resource Identifier
- URL
- Uniform Resource Locator
- VoiceXML
- Voice Extensible Markup Language
- W3C
- World Wide Web Consortium
- WICD
- Web Integration Compound Document
- WSDL
- Web Service Description Language
- Xforms
- XML application that represents the next generation of forms
- XHTML
- Extensible Hypertext Markup Language
- XML
- Extensible Markup Language
References
The W3C Technology Stack
http://www.w3.org/2004/10/RecsFigure.png
{kind=link}
About W3C Technology
http://www.w3.org/Consortium/technology
W3C Technical Reports and Publications esp. all Standards
http://www.w3.org/TR/
About W3C Activities
http://www.w3.org/Consortium/activities